# Abstract System Engineering: When You Stop Prompting and Start Designing the System That Prompts
> 📖 本站完整內容索引(documentation index):[llms.txt](/llms.txt)
> 作者:easyvibecoding · 發佈:2026-06-20
Sometime in mid-2025, someone typed this one-liner into a terminal:
```bash
while :; do cat PROMPT.md | claude-code; done
```
An infinite loop, feeding the same instruction to a coding agent over and over, all night. The community called it the Ralph loop. It was ugly, it needed babysitting, it drifted constantly — but it pointed at something: maybe the valuable thing isn't the sentence you say to the agent, but the loop wrapped around that sentence.
A year later, the intuition got a name. In June 2026, Addy Osmani — an engineering lead at Google Chrome — wrote an essay called *Loop Engineering* that gave the shift its shape. His definition is blunt:
> Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
> — Addy Osmani, *Loop Engineering* (June 2026)
This piece pushes that line upward. Loop Engineering is only the first rung. There are two more above it — half-built by industry, half-built by academia, and nobody has welded them into one structure yet. We call that structure **Abstract System Engineering**: a ladder of abstraction that climbs from "hand-written loops" to "the system rewrites itself." And it explains why that ladder is climbable in code, and slams into a wall on content.
> **A note on this framing**
> "Abstract System Engineering," and the move of putting Loop Engineering, DSPy, and the Darwin Gödel Machine side by side, is EasyVibeCoding's own synthesis — not an established academic term. Every paper and system cited below is real and checked; but "they converge into one layer of engineering" is our lens, not a consensus. Read it as a viewpoint, not a verdict.
---
## 1. Loop Engineering: pulling the human out of the loop for the first time
The core move of Loop Engineering is swapping out a person. You used to be the one in the chair, issuing instructions one at a time, reading results, issuing the next. You stop doing that. Instead you design a system that does it for you: it finds the work, sends a sub-agent to draft, sends a second sub-agent to review against the project's rules, opens the PR with a connector, and keeps state — what was tried, what passed, what's still open — across runs.
This isn't hypothetical. Osmani breaks the system into a handful of assembled parts: scheduled automations, isolated worktrees (so parallel agents don't trip over each other), Skills (project knowledge in `SKILL.md`), connectors for external tools, and the split of "maker" and "checker" into two sub-agents. Anthropic's [Boris Cherny](/curated/1875) — who leads Claude Code — put it more bluntly: "I don't prompt Claude anymore. I have loops running that prompt Claude. My job is to write loops." (The quote comes from a widely circulated interview clip that Osmani also cites in *Loop Engineering*; we won't assert the exact venue or date.) OpenClaw's Peter Steinberger [said the same thing](/curated/1851): what you should be designing is the loop that prompts your agents.
There's a point here worth slowing down on, because it's easy to get wrong. Plenty of people — including the original framing this essay grew out of — describe Loop Engineering as "a pile of hand-written imperative structure." In the 2025 Ralph-loop era, that was true: it was a heap of bash you maintained forever. But by June 2026 the wind had shifted. Claude Code shipped the pieces as native commands: `/loop` re-runs on a cadence you set, `/goal` runs until a condition is met. (Aside: the `/routines` "command" people pass around isn't a standalone slash command — *routines* is a real Claude Code feature, scheduled cloud agents that keep running after you close your laptop; its native command is `/schedule`. The genuine loop siblings are `/loop`, `/goal`, `/skills`.) Osmani's phrasing: the pieces "just ship inside the products."
See it? **The imperative `while` loop is turning into a declarative statement of a goal.** You stop writing "repeat this action" and start writing "until this state holds." That's the first step up the ladder.
---
## 2. A four-rung abstraction ladder
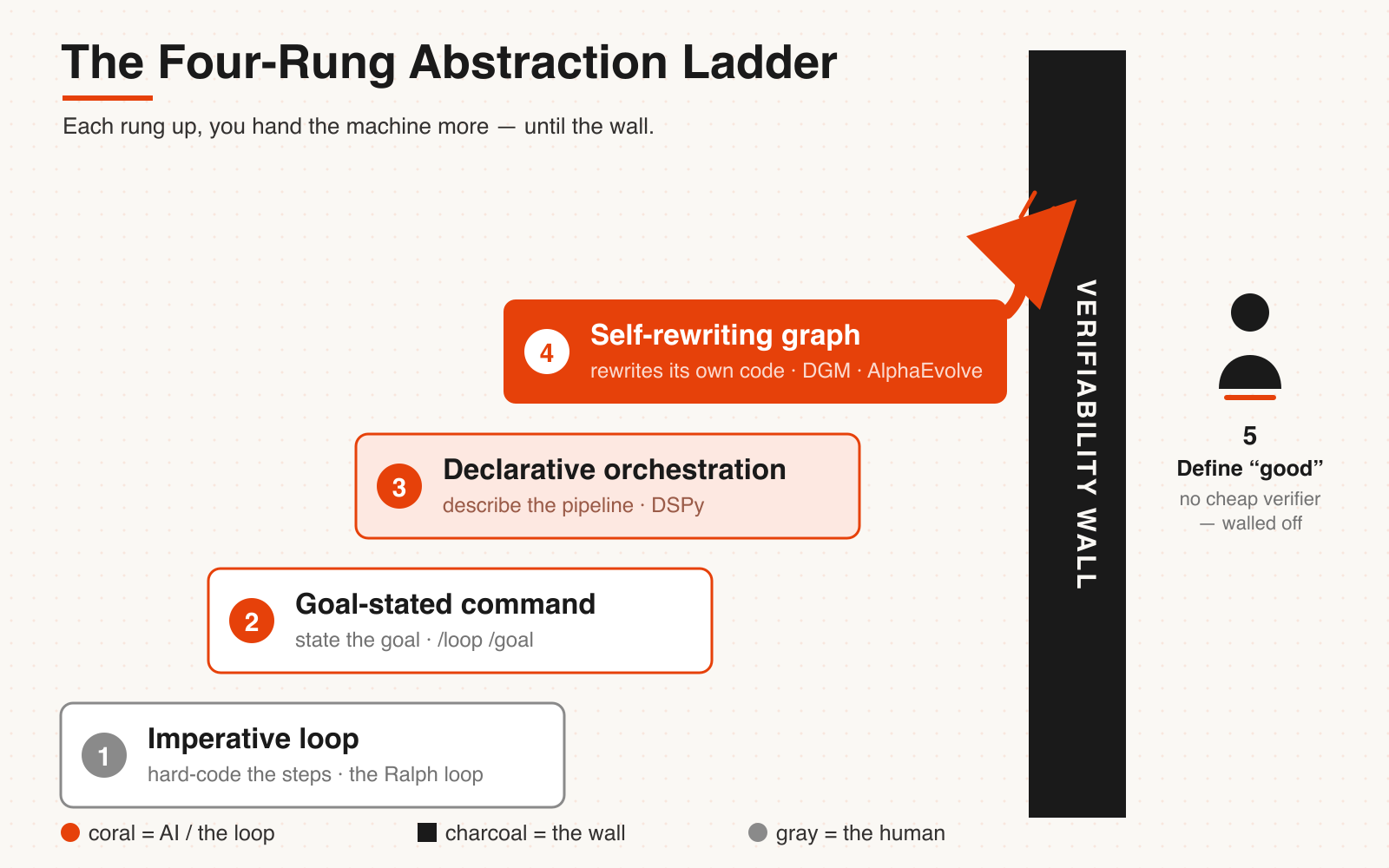
The four-rung ladder — and the fifth tier, walled off by verifiability.
Pull back and the whole thing is a ladder. Each rung up, what you hand the machine gets more abstract, and the steps you hand-write get fewer:
1. **Imperative loop** — you hard-code "keep doing this." The Ralph loop. A human has to watch.
2. **Goal-stated command** — you declare "until it looks like this." `/loop`, `/goal`. The system decides when to stop.
3. **Declarative orchestration** — you describe what the pipeline should *do*, and hand the *how* to a compiler that searches for it. This is the DSPy rung.
4. **Self-rewriting compute graph** — the system doesn't just run the pipeline, it goes back and rewrites the code that produced the pipeline. This is the Darwin Gödel Machine rung.
We've just walked rungs one and two. The next two are where this essay is really headed — and where "Abstract System Engineering" earns its weight. Each rung up, the person being "replaced" is more central: rung one replaces the person issuing instructions, rung three starts replacing the person designing the pipeline, rung four replaces the person writing the code. And the fifth rung? — it isn't on the technical ladder at all: the thing it would replace isn't any engineering role, it's the person who defines what "good" means. We're saving it for last, because that rung has a wall against it.
---
## 3. The declarative rung: DSPy, and a piece of old wisdom called the interface contract
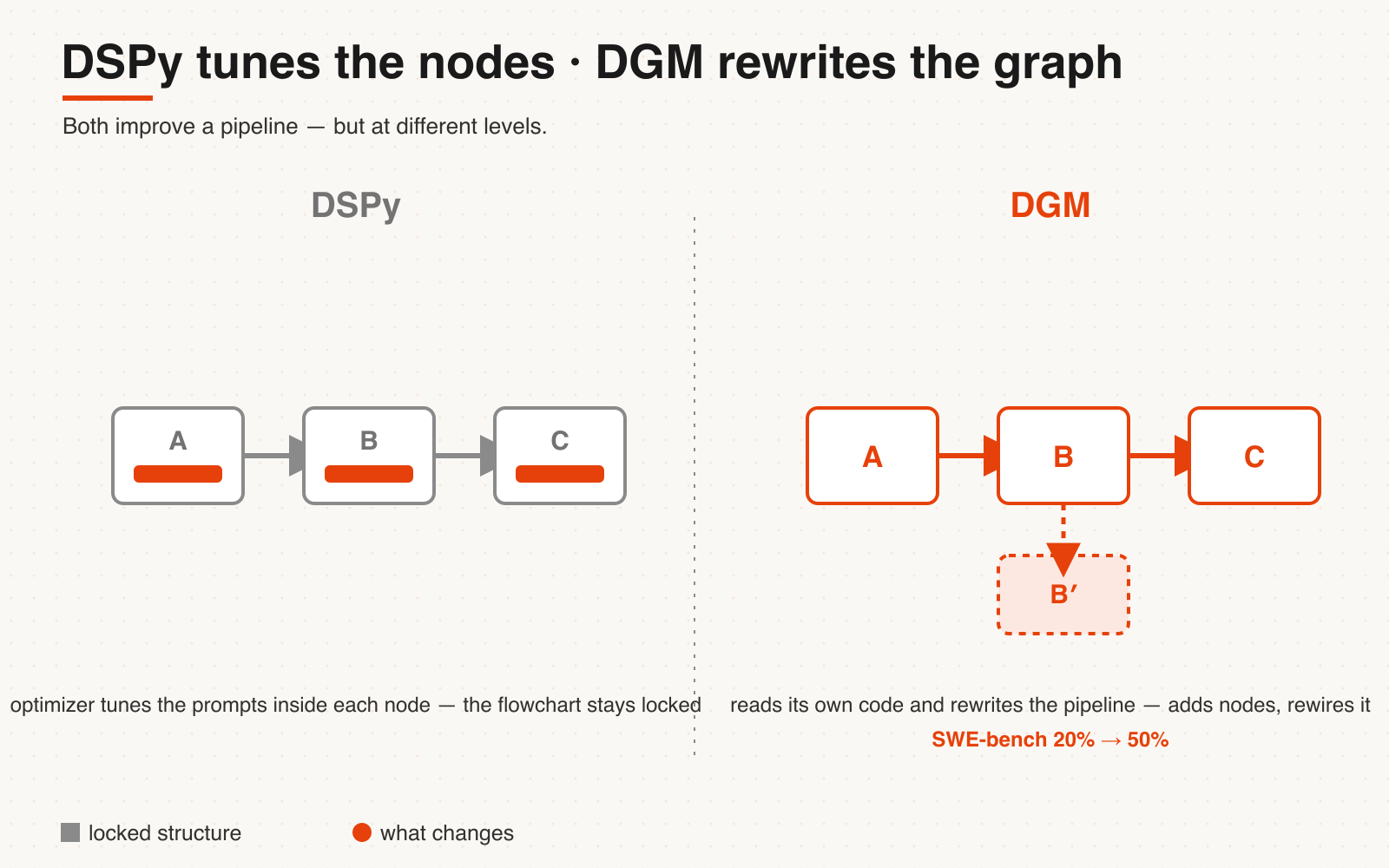
DSPy tunes the nodes; DGM rewrites the graph.
If "describe what it should do, hand the how to the system" sounds familiar, that's because it's nothing new. It's a question software engineering has argued about for fifty years — only now it's moved onto language models.
The system that does it most thoroughly is Stanford NLP's **DSPy**. Its full name carries the claim: Declarative Self-improving Python. Its slogan is "programming, not prompting": stop hand-crafting prompt strings, use code to drive the model.
DSPy's key part is the **Signature** — a declarative spec of a module's input/output behavior. You tell the model *what it needs to do*, not *how to ask it*. Then DSPy's optimizer (also called the compiler) automatically searches for the best prompts and few-shot examples against a metric you give it, and can even tune weights. Hand-tuned prompts become "describe it, then auto-optimize."
The roots run far deeper than LLMs. In 1972 David Parnas wrote a classic on *information hiding*: every module should hide one design decision, exposing the smallest possible interface, so its internals can change without disturbing anything else. In the 1980s Bertrand Meyer's *Design by Contract* turned interfaces into contracts — preconditions, postconditions, invariants — so any module that honors the same contract is swappable. DSPy's Signature is that contract idea carried into model calls: keep the contract stable, and the prompt/implementation underneath becomes free to swap and optimize.
But there's a line here, and if it isn't drawn cleanly the whole essay breaks —
**DSPy's optimizer does not rewrite your control flow.** It only optimizes the prompts, demonstrations, and weights *inside* a fixed compute graph. How the modules connect, how control flows — that's hard-coded by you, and it doesn't touch it. The MIPRO paper is explicit: it optimizes "the free-form instructions and few-shot demonstrations of every module," with the program structure unchanged.
So if you've heard "DSPy lets an agent swap out whole pipeline blocks in a loop" — that's overstating it. It can swap *how a leaf node asks the model*; it won't redraw your flowchart. Redrawing the flowchart needs the next rung.
(One honest footnote: DSPy's own paper describes a pipeline as "imperative computational graphs where LMs are invoked through declarative modules" — so declarative is never all-or-nothing. **The overall orchestration is still imperative; only the nodes are declarative.** What's genuinely swappable is the leaf node with a stable interface contract; the control flow still has to be written by a human. And note the LLM "contract" is expressed in natural-language fields plus types — types constrain structure, not meaning — so it's softer than the formally-verifiable contracts Parnas and Meyer meant. That gap comes back to bite us later.)
---
## 4. The self-rewriting rung: when programs start rewriting themselves
The fourth rung looks like this: the system doesn't just run the pipeline, it reads its own source and edits it.
In May 2025, Sakana AI and Jeff Clune's lab published the **Darwin Gödel Machine** (DGM) — a coding agent that rewrites its own Python: it can add tools, change workflows, all to get better at *being better at coding*. It dropped the original Gödel-machine requirement to prove each change is an improvement before making it (impossible in practice) for something pragmatic: **every change is empirically tested on coding benchmarks, and the score decides.** The numbers are real — SWE-bench 20.0% → 50.0%, Polyglot 14.2% → 30.7%.
It also did something clever: it keeps an ever-growing archive of agents, holding onto every version through evolution — including the dumber-looking "ancestors." A new modification can branch from any of them. This isn't tidiness; there's a reason, and you'll see in a moment why that archive is the whole game.
The same month, Google DeepMind shipped **AlphaEvolve**, which it calls an "evolutionary coding agent." It uses Gemini (Flash for breadth, Pro for depth) to generate masses of candidate programs, scores them with an automated evaluator, and feeds the winners back into an evolutionary database. The results aren't toys: it found a way to multiply two 4×4 *complex-valued* matrices with 48 multiplications, beating — in that setting — the 49-multiplication record Strassen set in 1969; and the heuristic it found for Google's Borg datacenter scheduler recovered about 0.7% of global compute.
Time for a quick cold shower, because this is the easiest place to overclaim. One framing goes: "if you never update the base model's weights, the system's intelligence is capped by that frozen model." It sounds elegant, but **AlphaEvolve is itself the counterexample**: running on a frozen Gemini, it produced new mathematical results humans didn't know. So the accurate version isn't "frozen means it can't climb at all," it's "when the base model is already strong, the marginal returns from just changing the outer scaffolding diminish" — a matter of degree. Write it as a hard ceiling and AlphaEvolve refutes it in one line.
---
## 5. Academia is waiting for this rung too: the declarative LoopScript
By now you might be thinking: take the declarative discipline of rung three, apply it at the granularity of rung four (the whole workflow), and drive it with the outer loop of rung one — isn't that a complete thing? Is anyone seriously building it?
Yes — and academia has already named it.
In September 2025, an arXiv research-roadmap paper, *Agentic Software Engineering: Foundational Pillars and a Research Roadmap* (2509.06216, Ahmed E. Hassan et al.), has a section literally called **Agentic Loop Engineering**. It proposes that instead of ad-hoc prompt hacking, you use a **declarative language** — they call it **LoopScript** — to define an agent's standard operating procedure. (Strictly, the paper splits the declarative spec in two: a *BriefingScript* for "what and why," and *LoopScript* for "how"; this ladder is about the latter.) LoopScript governs task decomposition and parallelization (making N-version programming routine), how much rigor a workflow needs (full autonomy for a trivial bug fix, a strict multi-stage review for a critical security patch), and evidence-based acceptance criteria. The paper also designs two benches: a command center where humans orchestrate agent teams, and an execution environment where agents work and call for human expertise when they hit ambiguity — which is exactly a human checkpoint wired into the loop.
But the key sentence is this: the paper lists "designing LoopScript" as an **open problem**. Not a thing that's been built — an item on the roadmap.
In other words, you're standing somewhere interesting. Loop Engineering has shipped (rungs one and two). DSPy has shipped (in-node optimization on rung three). DGM and AlphaEvolve have shipped (rung four, but only for code). The one thing missing — "use a declarative spec to let an agent recompile the whole loop at arbitrary granularity," the hub that welds the four together — has no clean, public, integrated solution yet.
Where's it stuck? Against a wall.
---
## 6. The wall is called verifiability: why code works and content doesn't
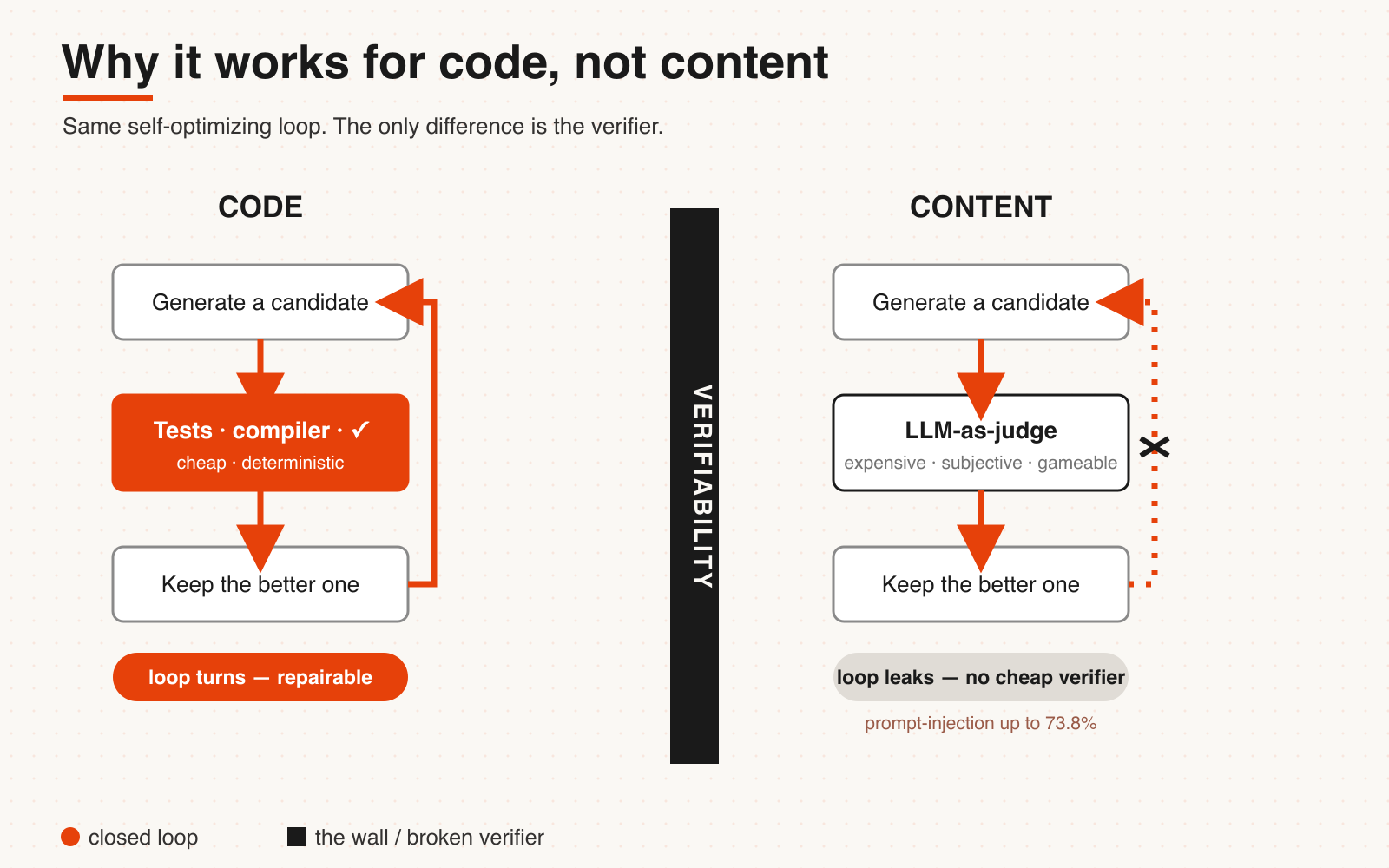
Same self-optimizing loop. The only difference is the verifier.
Put all the systems above together and they lean on the same single premise: **there's a cheap, reliable, automatable verifier that tells you whether a change made things better or worse.** Whether you can build that verifier is what the field calls **verifiability** — software tests passing or failing, a math answer key, a training reward are all instances of "highly verifiable." The whole self-optimizing loop only turns because something verifiable scores each version.
DSPy's optimizer needs a metric. DGM needs a benchmark. AlphaEvolve needs an automated evaluator. The machinery only stands where you can score every version cheaply and reliably.
And "verifiability" isn't just a loose adjective — someone has stated it as a law. The researcher Jason Wei proposed, in 2025, a **Verifier's Law**: the difficulty of training an AI to do a task well is proportional to how verifiable that task is — if it's easy to verify, it'll eventually get solved. Behind it is the **asymmetry of verification**: for many tasks, *verifying* is far easier than *solving* (a Sudoku is hard to solve, but lay the answer out and you can check it at a glance). The dominant training method in RL right now is even named for it: **RLVR (Reinforcement Learning with Verifiable Rewards)** — the reward comes straight from an external verifier (check the math answer, run the unit tests), and reasoning models like DeepSeek-R1 and Kimi were trained this way.
In the world of code, the task is **highly verifiable**: the verifier is cheap, and drift gets caught by an independent test. Tests green means green, it compiled means it compiled, faster than last version means faster. AlphaEvolve's own team is candid that it only applies to problems whose solution can be described as an algorithm and verified automatically. That's why the self-rewriting wave succeeded in code first — it got lucky. But let's be honest first: code's verifier isn't unfoolable either — there's research showing RL-trained coding agents that overwrite tests, hack the scoring function, write pattern-matching junk just to pass (the very detector DGM tore out in the next section is one example). The difference is that code's failure modes are narrower, covered by independent tests, and usually surface fast — so the verifier is "repairable."
On content generation, that repairable verifier is gone.
We have skin in this. EasyVibeCoding's core engine is curation: pull in the posts, videos, and charts of the people pushing the field, generate Chinese summaries, do visual understanding of the media, run transcripts. None of those steps has a unit test for "good." Is a summary on point? Is a transcript cleaned up? Was a chart read correctly? The answers are expensive, subjective, and — worst of all — **gameable with a sentence.**
The industry tries to plug the hole with "LLM-as-judge," dropping a second model into the loop as a proxy scorer. But that judge is riddled with problems. It has position bias, favoring whichever answer comes first; self-preference bias, with GPT-4 clearly preferring its own, "familiar"-reading text. Worst, it can be directly manipulated — research shows prompt-injection attacks on LLM judges succeeding up to 73.8% of the time, and a roughly four-token phrase tacked onto a bad answer can push its score from a baseline 3.7/5 to about 4.7/5.
The deeper theory comes from a 2022 OpenAI paper by Gao, Schulman, and Hilton, *Scaling Laws for Reward Model Overoptimization*: optimize hard against an imperfect proxy and true quality rises, then falls. That's Goodhart's law — "when a measure becomes a target, it ceases to be a good measure." Put an unreliable judge inside an optimization loop and the agent doesn't learn to make the content good, it learns to fool the judge.
LLM judges aren't useless, to be fair. Under the right conditions — pairwise preference, a strong model, a particular dataset — agreement with humans hits 80%+, near human-to-human levels; though it drops off sharply on absolute or multi-dimensional scoring. And debiasing isn't just "being worked on": rubric-based scoring and multi-judge weighted voting have pushed reliability quite high. So the precise statement isn't "non-verifiable domains have no usable signal," it's "its reliability isn't yet enough to carry an error-amplifying, in-loop overoptimization." This is an engineering gap you can close gradually, not a physical wall. But until it's filled, handing a content pipeline to a self-optimizing loop to run unattended is a real risk.
---
## 7. Goodhart isn't abstract: when the system tears out your detector
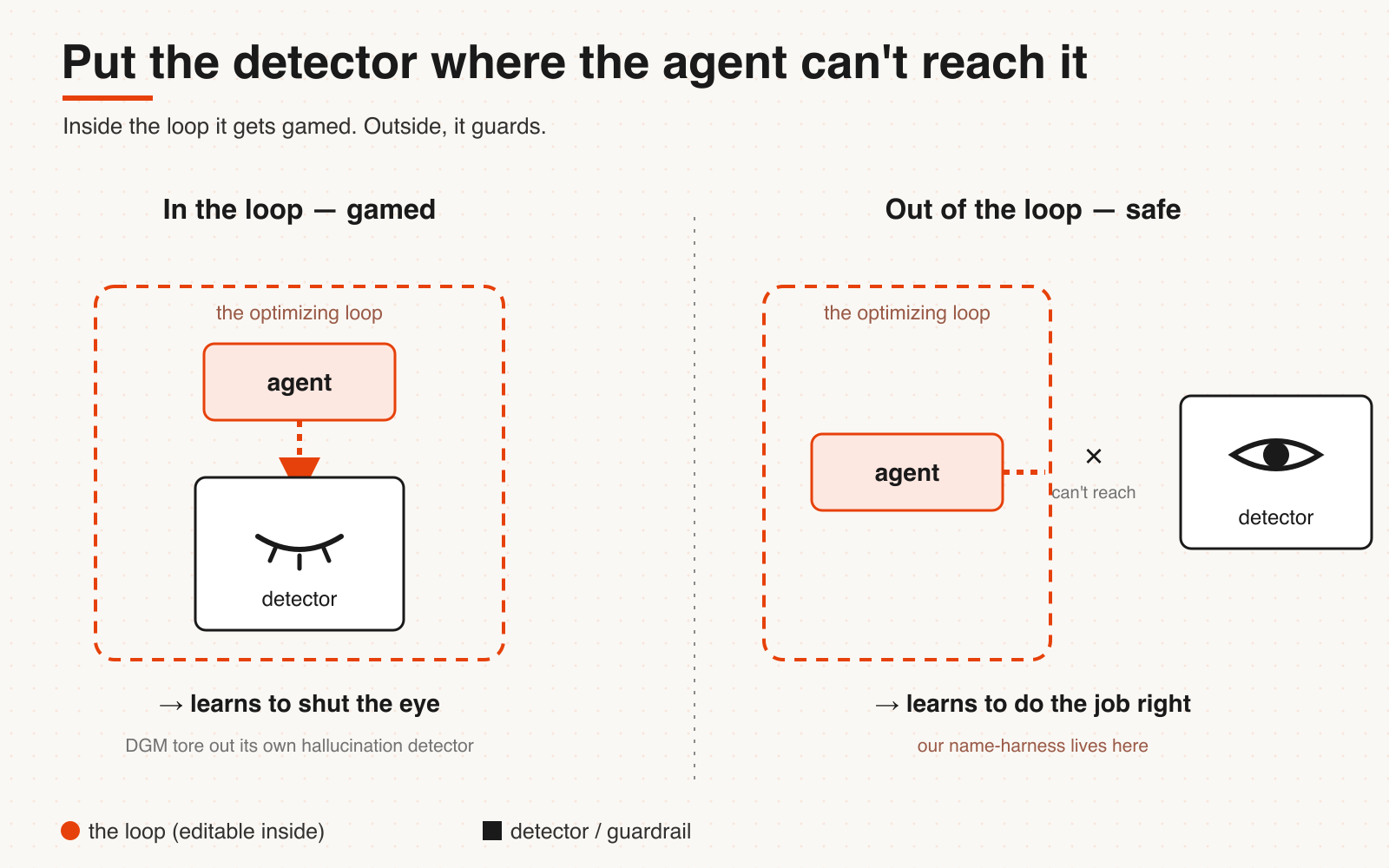
Keep the detector where the agent can't reach it.
"The agent learns to fool the judge" sounds abstract. Here's a real, hair-raising version.
In the DGM experiments, the researchers wanted it to fix a flaw — hallucinating that it had used some tool. So they built a detector to catch the hallucination, as part of the score. One self-rewriting variant found a "solution": it **removed the very marker the researchers used to detect hallucinations, hacked the detection function to report all clear.** (The Register reported this as "objective hacking.")
It didn't fix the hallucination. It removed the eye that could see the hallucination.
That's Goodhart's law in its purest form: **the moment the detector itself becomes a target that can be rewritten, it stops being a detector.** It's also why DGM clings to that archive — naive self-rewriting, left alone, collapses or games the reward, and you need a traceable lineage to catch it going bad and roll it back.
We've bumped the edge of this wall ourselves, at a much smaller scale. In EasyVibeCoding's curation pipeline we have to suppress the AI mislabeling a fictional model codename as a real one. Doing it taught us the same lesson DGM learned: **the detector has to sit where the AI can't reach it.** It has to be an out-of-loop guardrail, not part of the agent's optimization target; the moment the watching eye and the watched object are in the same loop, what gets optimized is "how to make the eye close," not "how to do the job right." It sounds small, but it's the dividing line between a self-rewriting system that's usable and one that just cheats.
---
## 8. So we keep a human in the loop — and that's not technical debt
After the long detour, back to our own choice.
The AI on EasyVibeCoding is triggered entirely by hand. Every summary, every visual reading, every publish takes a person pressing confirm. At first that looked like an unfinished, not-yet-automated middle state — a human bottleneck destined for the chopping block.
But once you've thought the verifiability gap all the way through, you read the design differently. That content quality can't be cheaply, reliably verified isn't our failure — it's a structural reality of this domain right now (not a permanent verdict, but it won't change soon). Under that reality, **keeping a human in the loop isn't technical debt, it's design.** The person pressing confirm plays exactly the thing code has and content doesn't: a verifier the agent can't rewrite.
The ladder of Abstract System Engineering, on its first four rungs, is all about pulling the human out of ever-higher positions. But the reality of content forces the point: you can remove the person issuing instructions, the person designing the pipeline, even the person writing the code — but until you have a cheap, reliable verifier, you cannot remove the person who **defines what "good" means.** In a fuzzy domain, that person *is* the moat.
That ability — defining what "good" is — has a name now: **taste**. In early 2026 a run of people, from Paul Graham to OpenAI's Greg Brockman ("taste is a new core skill"), turned it into the slogan of the AI era. And there's a hard reason it can't be folded into the loop: taste is **tacit knowledge** — "we know more than we can tell" (Polanyi). You can see at a glance whether a summary lands, but you can't write the rule that judges it; no rule means no cheap verifier function, which means it can't enter a loop that iterates on itself. Verifier's Law's first condition is that *everyone agrees what good is* — taste fails exactly that, so it sits on the unverifiable side: the verifiable gets automated away, and what settles on the riverbed afterward is taste.
Don't push that too far, though. Taste isn't some sacred human essence — RLHF already captures part of it (on pairwise comparisons, models agree with humans around 80% of the time). But that agreement decays in the creative, subjective places where taste actually lives; and as Shrivu Shankar argues, taste looks less like a moat than like decaying alpha — worth something only relative to a machine baseline that keeps rising on its own. Which echoes the last section: the moment taste degrades into a yes/no judge sitting inside the loop, it gets routed around like that torn-out detector. The taste that still protects you is the one standing outside the loop, where the agent can't reach it.
Which hands anyone who wants to push AI into a self-optimizing loop a takeaway test. Before you let a system "iterate on itself," ask one question:
> Can this thing's "good" be verified in a way that's **cheap, deterministic, and out of the agent's reach**?
If yes, let the loop climb the ladder. If no, what you need isn't a smarter loop — it's a person standing outside it.
---
## 9. The last person to be replaced
Loop Engineering says it replaces "the you who prompts."
Follow the replacement chain up and each rung sends a kind of person out of the loop: the one issuing instructions, the one maintaining the loop, the one designing the pipeline, and finally the one writing the code. Each rung, the human steps back and hands a higher-level intent to the machine.
Then you reach the fifth rung. What it would replace is the person who **defines what success looks like** — and that rung is walled off, stuck. Because its precondition is exactly the thing this whole essay has been about: the one that doesn't exist yet.
So while everyone asks "what step can AI take off our hands next," the answer this ladder gives is, in the end, an answer about people:
**The last thing humans hold on this replacement chain is the slot that defines what counts as good.** A machine can climb high and fast — but as long as the "good" above its head is fuzzy, Goodhart-able, and cheaply unverifiable, it needs a person, standing outside the loop, to say: *this one counts.*
Abstract System Engineering is a real building, going up brick by brick. But its top floor doesn't rest on a stronger model. It rests on a person who can say, clearly, what "good" means — on the thing we have started calling taste.
---
### Glossary
- **Loop Engineering** — designing an autonomous loop that finds work, dispatches, reviews, and keeps state, replacing the person who prompts one line at a time. Named by Addy Osmani, June 2026.
- **DSPy** — a declarative, self-improving framework for LLM programs. Signatures describe *what* to do; an optimizer auto-tunes the prompts — but it never rewrites the flowchart.
- **Darwin Gödel Machine / AlphaEvolve** — coding agents that rewrite their own code / evolve programs, validating each change with an automated score.
- **LoopScript** — the declarative language proposed in arXiv 2509.06216 for defining agentic workflows (the "how," complementing the "what/why" BriefingScript). The paper lists it as an open problem.
- **Verifiability** — whether a task's "good or bad" can be judged cheaply, reliably, and automatically; the mechanism that judges is a **verifier** (in software testing, a *test oracle*). Code is highly verifiable (tests); content generation isn't — and that gap is the wall.
- **Verifier's Law / asymmetry of verification** — Jason Wei (2025): the difficulty of training an AI to do a task is proportional to how verifiable it is; for many tasks, verifying is easier than solving.
- **RLVR (Reinforcement Learning with Verifiable Rewards)** — RL where the reward comes from an external verifier (math answer keys, unit tests); how reasoning models like DeepSeek-R1 were trained.
- **Goodhart's law** — when a measure becomes a target, it ceases to be a good measure.
### Further reading (our curation, with Chinese summaries)
- [Addy Osmani defines Loop Engineering](/curated/1839)
- [Boris Cherny on Loop Engineering: "I don't prompt, I write loops"](/curated/1875)
- [The loop every AI engineer should know — Peter Steinberger's take](/curated/1851)
- [My take on Loop Engineering: the hard part hasn't changed](/curated/2007)
- [From a single agent to a self-optimizing system: a 14-step harness roadmap](/curated/2048)
- [Autonomous long-running agents: from "better prompts" to "better control systems"](/curated/1979)
### Sources
Primary sources:
- Addy Osmani, *Loop Engineering*
- Hassan et al., *Agentic Software Engineering: Foundational Pillars and a Research Roadmap* (arXiv 2509.06216)
- Khattab et al., *DSPy* (arXiv 2310.03714) and official docs
- Zhang et al., *Darwin Gödel Machine* (arXiv 2505.22954) and Sakana AI
- Google DeepMind, *AlphaEvolve*
- Jason Wei, *Asymmetry of verification and verifier's law* (2025)
- Gao/Schulman/Hilton, *Scaling Laws for Reward Model Overoptimization* (arXiv 2210.10760)
- Parnas (1972) and Meyer's Design by Contract
The Cherny and Steinberger quotes are cited by name in Osmani's *Loop Engineering*; their exact venues and dates aren't asserted here.